Last, we learned about classification for binary and multiclass problems.
Missing data in research
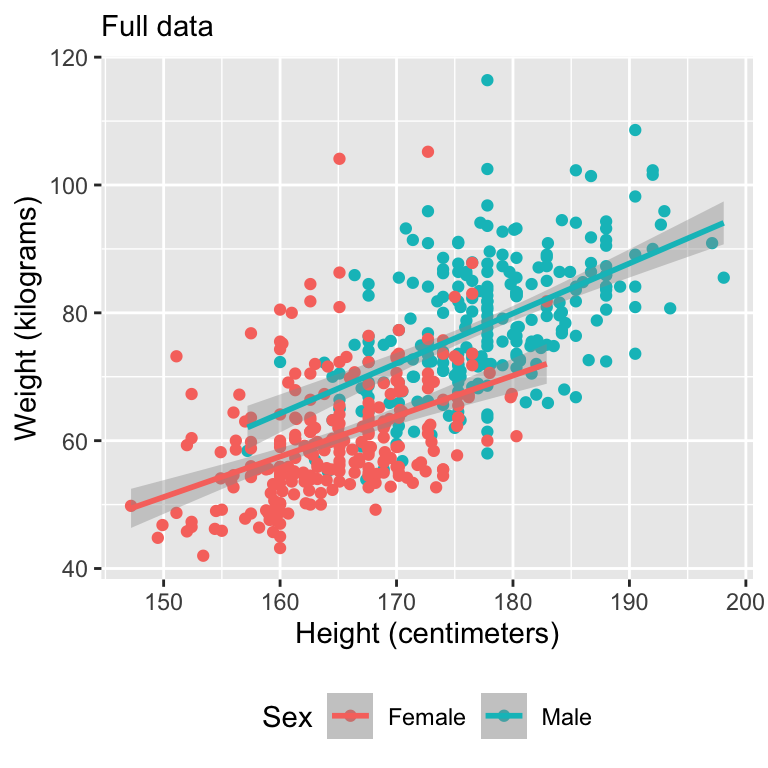
In any real-world dataset, missing values are nearly always going to be present.
Missing data can be totally innocuous or a source of bias.
Cannot determine which because there are no values to inspect.
Handling missing data is extremely difficult!
Example
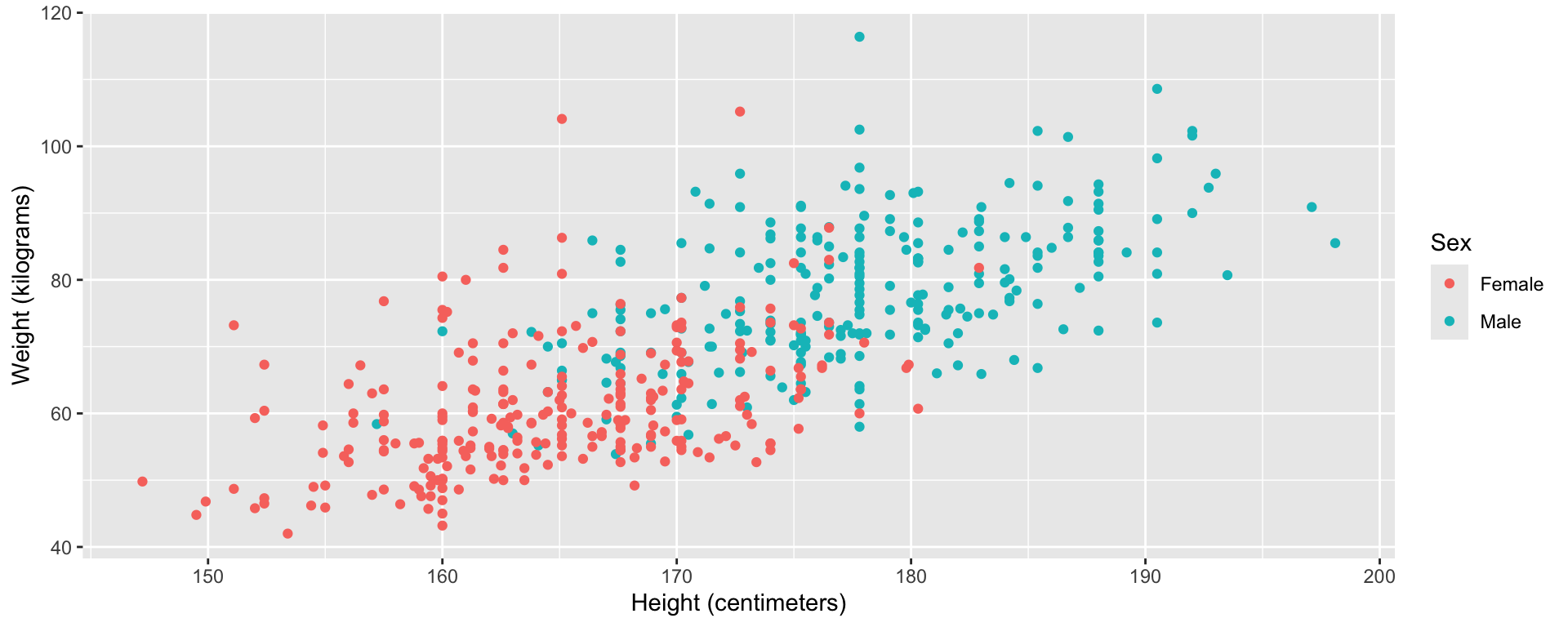
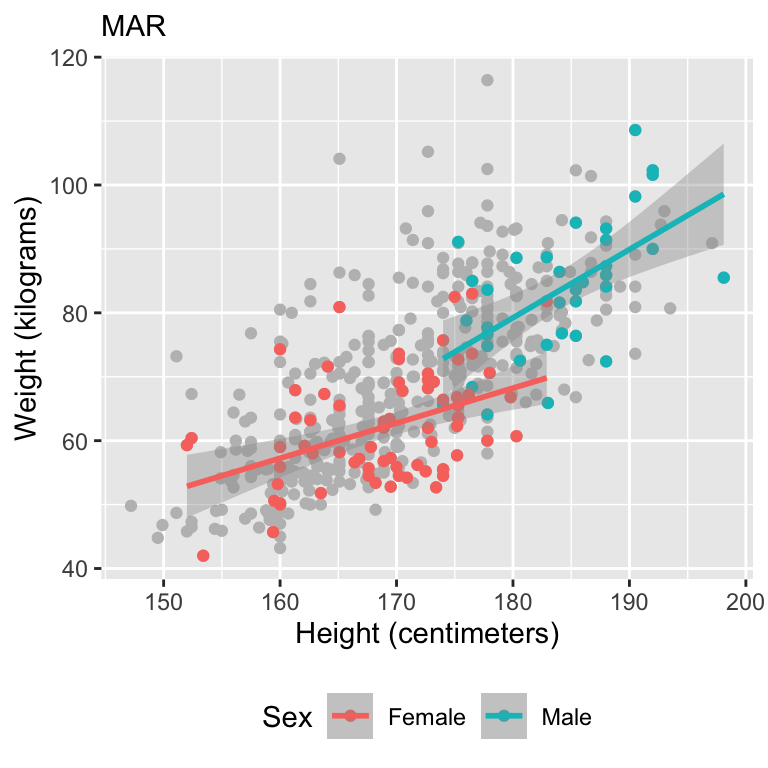
Suppose an individual’s depression scores are missing in dataset of patients with colon cancer.
It could be missing because:
A data entry error where some values did not make it into the dataset.
The patient is a man, and men are less likely to complete the depression score in general (i.e., it is not related to the unobserved depression).
The patient has depression and as a result did not complete the depression survey.
Classifactions of missing data
Missing completely at random (MCAR)
This is the ideal case but rarely seen in practice. Usually a data entry problem.
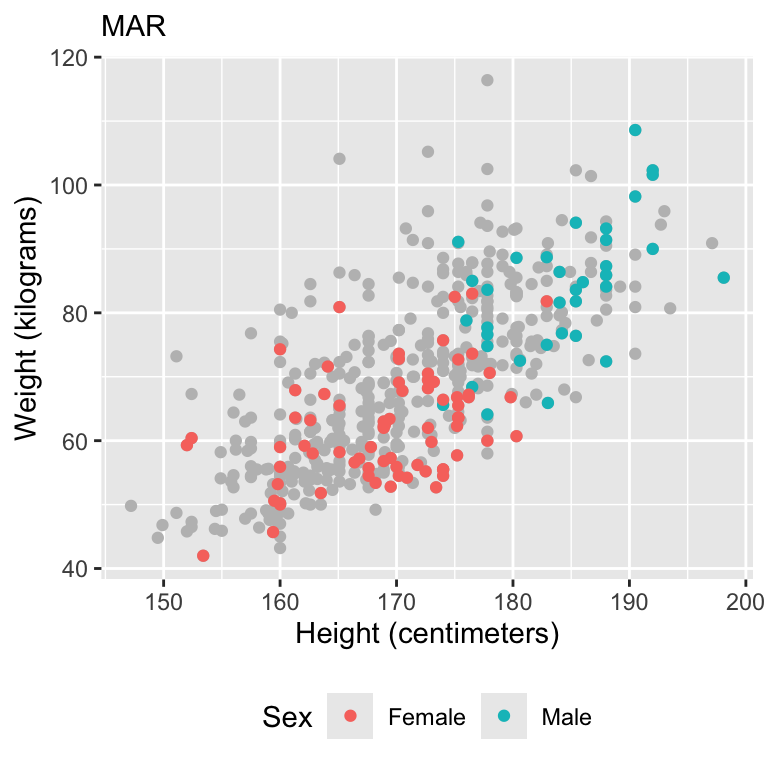
Missing at random (MAR)
The missing value is related to some other variable that has been collected.
Missing not at random (MNAR)
The missing value is related to a variable that was not collected or not observed.
Missing data
Missing data can appear in the outcome and/or predictors.
Today, we will write down some math for missing data occuring in the outcome space, however this is generalizable to missingness in the predictor space.
Missing data framework
We are interested in modeling a random variable \(Y_{i}\), for \(i \in \{1,\ldots,n\}\).
In a missing data setting, we only observe the outcome in subset of observations, \(\mathbf{Y}_{obs} = \{Y_{i}:i \in \mathcal N_{obs}\}\).
\(\mathcal N_{obs}\) is the set of indeces in the observed set, such that \(|\mathcal N_{obs}|= n_{obs}\) is the number of observed data points.
The remaining observations are assumed to be missing and are contained in \(\mathbf{Y}_{mis} = \{Y_{i}:i \in \mathcal N_{mis}\}\).
\(\mathcal N_{mis}\) is the set of indeces of the missing data and \(|\mathcal N_{mis}|= n_{mis}\) is the number of missing data points.
The full set of data is given by \(\mathbf{Y}=(\mathbf{Y}_{obs},\mathbf{Y}_{mis})\).
Missing data notation
Define \(O_{i}\) as a binary indicator of observation \(Y_{i}\) being present, where \(O_{i} = 1\) indicates that \(Y_{i}\) was observed.
The collection of missingness indicators is given by \(\mathbf{O} = \{O_{i}:i = 1,\ldots,n\}\).
Our observed data then consists of \((\mathbf{Y}_{obs}, \mathbf{O})\).
Complete data likelihood
The joint distribution of \((\mathbf{Y}, \mathbf{O})\) can be written as,
The data are missing completely at random (MCAR) if the missing mechanism is defined as, \[\begin{aligned}
f(\mathbf{O} | \mathbf{Y},\mathbf{X},\boldsymbol{\phi}) &= f(\mathbf{O} | \mathbf{Y}_{obs}, \mathbf{Y}_{mis},\mathbf{X},\boldsymbol{\phi})\\
&= f(\mathbf{O} | \boldsymbol{\phi}).
\end{aligned}\]
No bias: The analysis based on the observed data will not be biased, as the missingness does not systematically favor any particular pattern in the data.
Reduced power: While unbiased, MCAR still reduces the statistical power of the analysis due to the smaller sample size resulting from missing data.
Simple handling methods: Because of its random nature, MCAR allows for straightforward handling methods like listwise deletion (i.e., complete-case analysis) or simple imputation techniques (e.g., mean imputation) without introducing bias.
Missing data models: MAR
The data are missing at random (MAR) if the missing mechanism is defined as, \[\begin{aligned}
f(\mathbf{O} | \mathbf{Y},\mathbf{X},\boldsymbol{\phi}) &= f(\mathbf{O} | \mathbf{Y}_{obs}, \mathbf{Y}_{mis},\mathbf{X},\boldsymbol{\phi})\\
&= f(\mathbf{O} | \mathbf{Y}_{obs},\mathbf{X},\boldsymbol{\phi}).
\end{aligned}\]
The missingness depends on the observed data only.
Unbiased Parameter Estimates: Similar to MCAR, we can perform a complete case analysis and can ignore the missing data model! This is never done, however, because it leads to incorrect inference.
Key points about MAR assumption
Complete-case analysis is not acceptable:
Parameter estimation remains unbiased, but, in general, estimation of variances and intervals is biased.
Also, smaller sample size leads to less power and worse prediction.
Under certain missingness settings, parameter estimation may not be unbiased.
Simple handling approaches fail: Methods like mean imputation will also result in small estimated standard errors.
More advanced methods are needed: Multiple imputation, Bayes.
Missing data models: MNAR
The data are missing not at random (MNAR) if the missing mechanism is defined as, \[\begin{aligned}
f(\mathbf{O} | \mathbf{Y},\mathbf{X},\boldsymbol{\phi}) &= f(\mathbf{O} | \mathbf{Y}_{obs}, \mathbf{Y}_{mis},\mathbf{X},\boldsymbol{\phi}).
\end{aligned}\]
The missingness depends on the observed and missing data.
Under the MNAR assumption, we are NOT allowed to ignore the missing data. We must specify a model for the missing data.
This is really hard! We can ignore this in our class.
Summary of missing mechanisms
Under MCAR and MAR, we are allowed to fit our model to the observed data (i.e., a complete case analysis/listwise deletion). Under these settings the missingness is considered ignorable.
Under MAR, fitting the complete case analysis is not efficient and advanced techniques are needed to guarentee proper statistical inference.
Under MNAR, we must model the missing data mechanism. This data is considered non-ignorable.
We can simplify this posterior by dropping the missing data mechanism.
Full Bayesian model
Assuming that \(f(\boldsymbol{\theta},\boldsymbol{\phi}) = f(\boldsymbol{\theta})f(\boldsymbol{\phi})\), the missingness process does not need to be explicitly modeled when we are interested in inference for \(\boldsymbol{\theta}\).
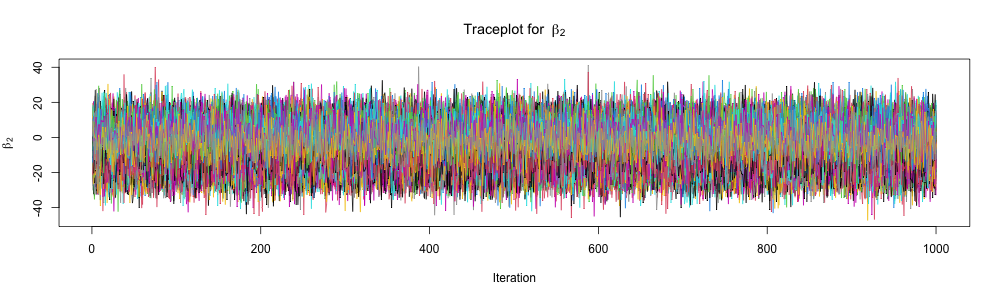
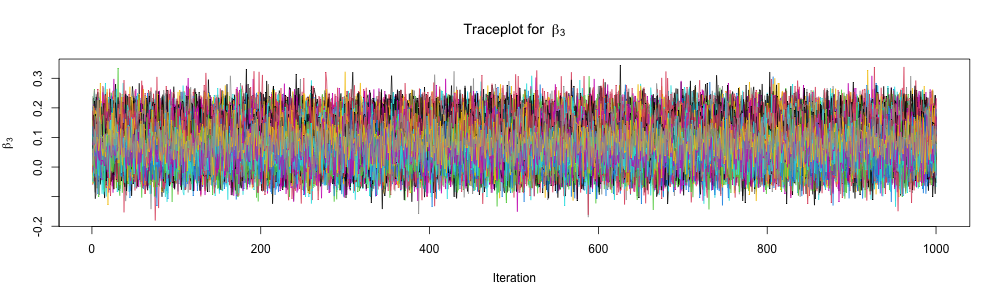
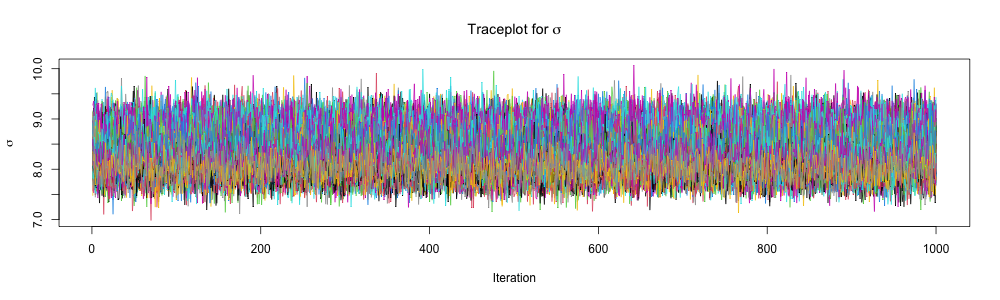
print(fit_full_bayes_joint, pars =c("alpha", "beta", "sigma"), probs =c(0.025, 0.975))
Inference for Stan model: anon_model.
4 chains, each with iter=2000; warmup=1000; thin=1;
post-warmup draws per chain=1000, total post-warmup draws=4000.
mean se_mean sd 2.5% 97.5% n_eff Rhat
alpha -48.38 0.83 21.10 -90.15 -7.03 653 1.00
beta[1] 0.65 0.00 0.12 0.41 0.90 673 1.00
beta[2] -3.19 0.22 9.75 -22.23 16.56 2047 1.00
beta[3] 0.08 0.00 0.06 -0.03 0.19 2487 1.00
sigma 8.21 0.02 0.58 7.17 9.45 600 1.01
Samples were drawn using NUTS(diag_e) at Wed Jan 22 19:43:45 2025.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).
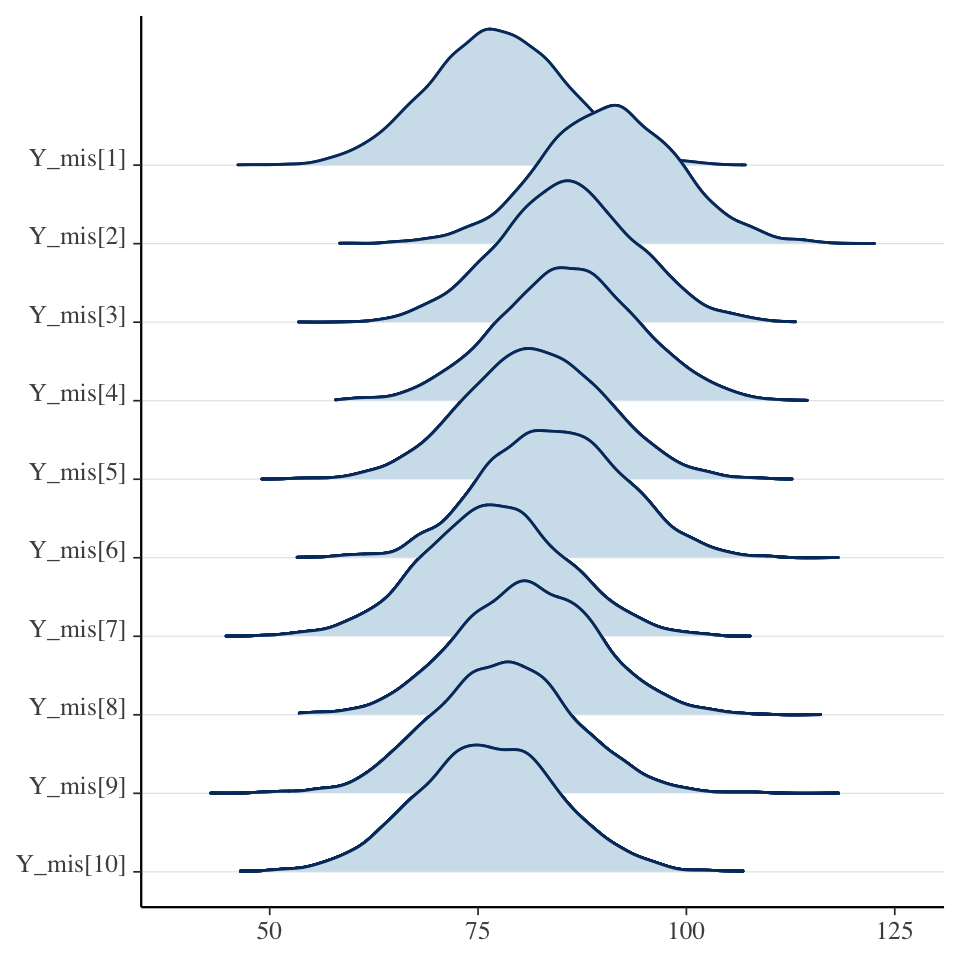
Explore latent missing variable
library(bayesplot)Y_mis <- rstan::extract(fit_full_bayes_joint, pars ="Y_mis")$Y_miscolnames(Y_mis) <-paste0("Y_mis[", 1:ncol(Y_mis), "]")mcmc_areas_ridges(Y_mis[, 1:10])
Summary of Bayesian joint model
The joint model treats the missing data as parameters (i.e., latent variables in the model).
Placing a prior on the missing data allows us to jointly learn the model parameters and the missing data.
Equivalent to multiple imputation at every step of the HMC. Can be slow!
In Stan, we can only treat continuous missing data as parameters, so this method is somewhat limited (what do we do if the missing data is a binary outcome?)
Multiple imputation
As an alternative to fitting a joint model, there are many approaches that allow us to impute missing data before the actual model fitting takes place.
Each missing value is not imputed once but \(m\) times leading to a total of \(m\) fully imputed data sets.
The model can then be fitted to each of those data sets separately and results are pooled across models, afterwards.
One widely applied package for multiple imputation is mice (Buuren & Groothuis-Oudshoorn, 2010) and we will use it in combination with Stan.
Mice
Here, we apply the default settings of mice, which means that all variables will be used to impute missing values in all other variables and imputation functions automatically chosen based on the variables’ characteristics.
library(mice)m <-100mardata <-data.frame(y = fulldata$y,x1 = fulldata$x1,x2 = fulldata$x2)mardata$y[fulldata$o ==0] <-NAimp <-mice(mardata, m = m, print =FALSE)
Mice
Now, we have \(m = 5\) imputed data sets stored within the imp object.
In practice, we will likely need more than 5 of those to accurately account for the uncertainty induced by the missingness, perhaps even in the area of 100 imputed data sets (Zhou & Reiter, 2010).
We can extract the first imputed dataset.
data <-complete(imp, 1)
We can now fit our model \(m\) times for each imputed data sets and combine the posterior samples from all chains for inference.
stan_bayesian_mi <-stan_model(file ="bayesian-mi.stan")alpha <- beta <- sigma <- r_hat <- n_eff <-NULLn_chains <-2for (i in1:m) {###Load each imputed dataset and fit the Stan complete case model data <-complete(imp, i) X <-model.matrix(~ x1 * x2, data = data)[, -1, drop =FALSE] stan_data_bayesian_mi <-list(n =nrow(data),p =ncol(X),Y = data$y,X = X ) fit_mi <-sampling(stan_bayesian_mi, stan_data_bayesian_mi, chains = n_chains)###Save convergence diagnostics from each imputed dataset r_hat <-cbind(r_hat, summary(fit_mi)$summary[, "Rhat"]) n_eff <-cbind(n_eff, summary(fit_mi)$summary[, "n_eff"]) pars <- rstan::extract(fit_mi, pars =c("alpha", "beta", "sigma"))### Save the parameters from each imputed dataset n_sims_chain <-length(pars$alpha) / n_chains alpha <-rbind(alpha, cbind(i, rep(1:n_chains, each = n_sims_chain), pars$alpha)) beta <-rbind(beta, cbind(i, rep(1:n_chains, each = n_sims_chain), pars$beta)) sigma <-rbind(sigma, cbind(i, rep(1:n_chains, each = n_sims_chain), pars$sigma))}