u = center(observed and prediction locations)
S = box size (u)
max_iter = 30
# initialization
j = 0
check = FALSE
rho = 0.5*S # the practical paper recommends setting the initial guess of rho to be 0.5 to 1 times S
c = c(rho/S) # minimum c given rho and S
m = m(c,rho/S) # minimum m given c, and rho/S
L = c*S
diagnosis = logical(max_iter) # store checking results for each iteration
while (!check & j<=max_iter){
fit = runHSGP(L,m) # stan run
j = j + 1
rho_hat = mean(fit$rho) # obtain fitted value for rho
# check the fitted is larger than the minimum rho that can be well approximated
diagnosis[j] = (rho_hat + 0.01 >= rho)
if (j==1) {
if (diagnosis[j]){
# if the diagnosis check is passed, do one more run just to make sure
m = m + 2
c = c(rho_hat/S)
rho = rho(m,c,S)
} else {
# if the check failed, update our knowledge about rho
rho = rho_hat
c = c(rho/S)
m = m(c,rho/S)
}
} else {
if (diagnosis[j] & diagnosis[j-2]){
# if the check passed for the last two runs, we finish tuning
check = TRUE
} else if (diagnosis[j] & !diagnosis[j-2]){
# if the check failed last time but passed this time, do one more run
m = m + 2
c = c(rho_hat/S)
rho = rho(m,c,S)
} else if (!diagnosis[j]){
# if the check failed, update our knowledge about rho
rho = rho_hat
c = c(rho/S)
m = m(c,rho/S)
}
}
L = c*S
}Scalable Gaussian Processes #2
Apr 03, 2025
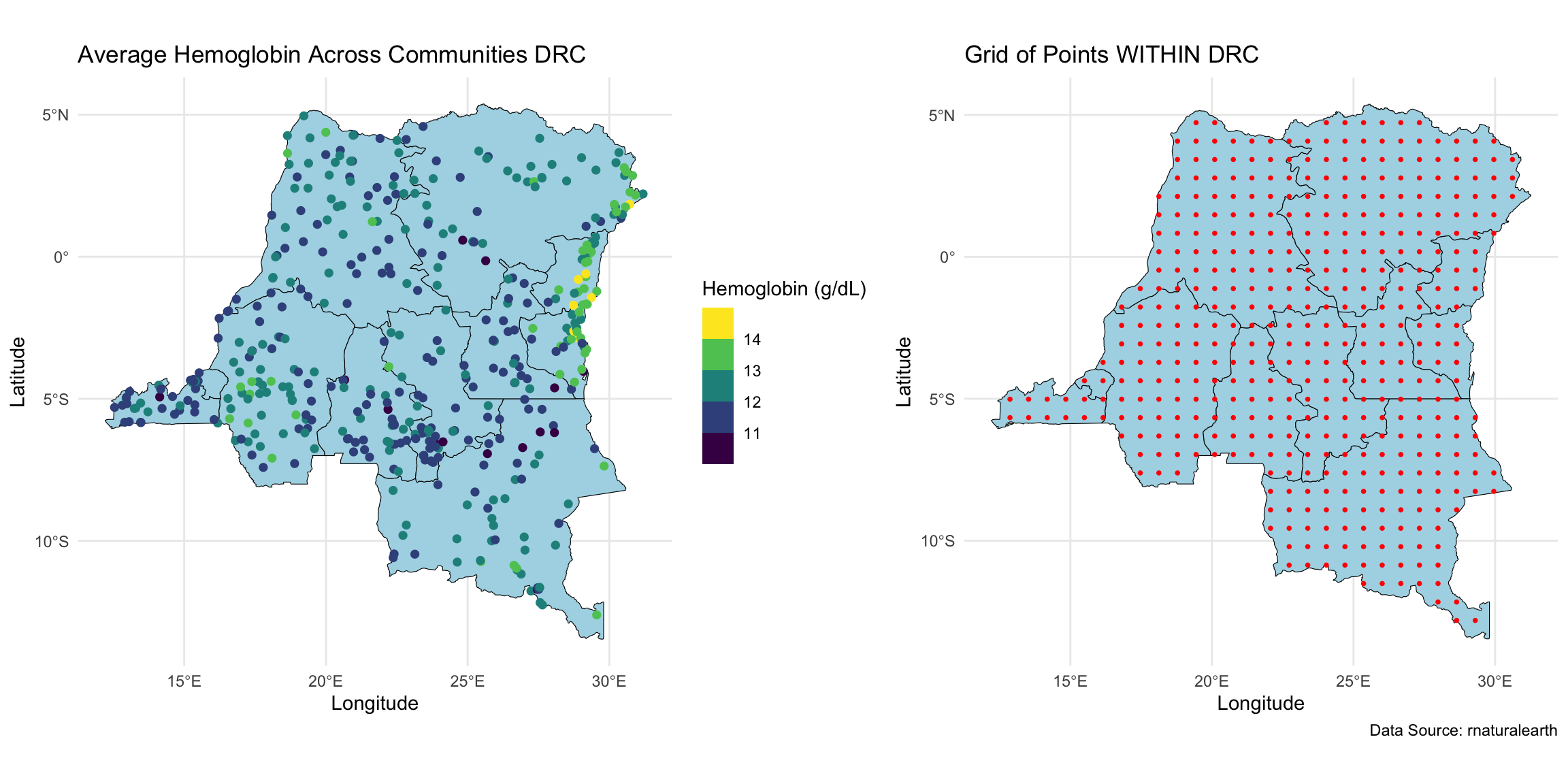
Geospatial analysis on hemoglobin dataset
We wanted to perform geospatial analysis on a dataset with ~8,600 observations at ~500 locations, and make predictions at ~440 locations on a grid.
HSGP approximation box and \(\rho\)
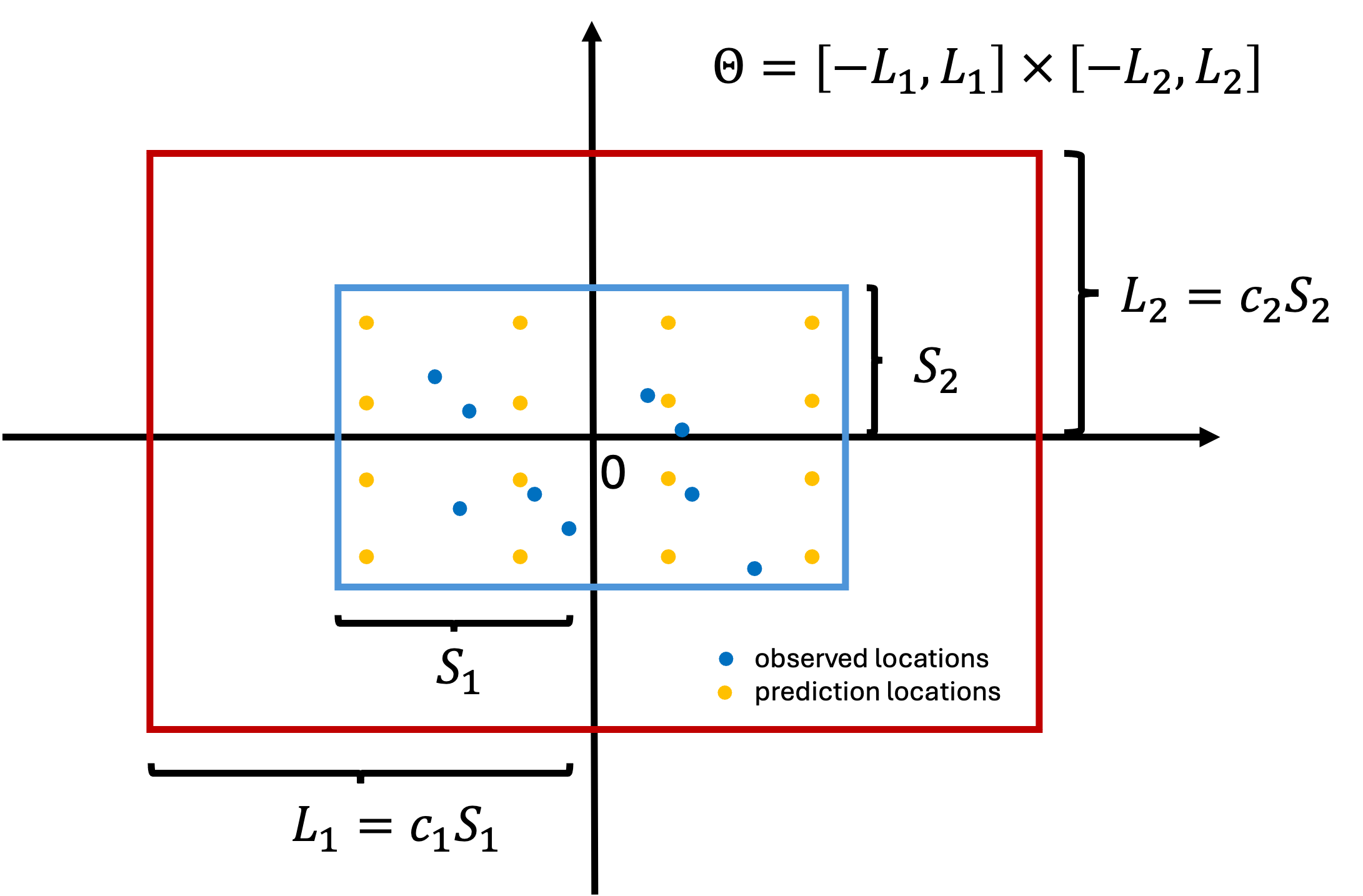
How much the approximation accuracy deteriorates towards the boundaries depends on smoothness of the true surface.
- the larger the length scale \(\rho\), the smoother the surface, a smaller box (smaller \(c\)) can be used for the same level of boundary accuracy.
HSGP approximation box and \(m\)
The larger the box,
- the more basis functions we need for the same level of overall accuracy,
- hence higher run time.
Zooming out doesn’t simplify the problem
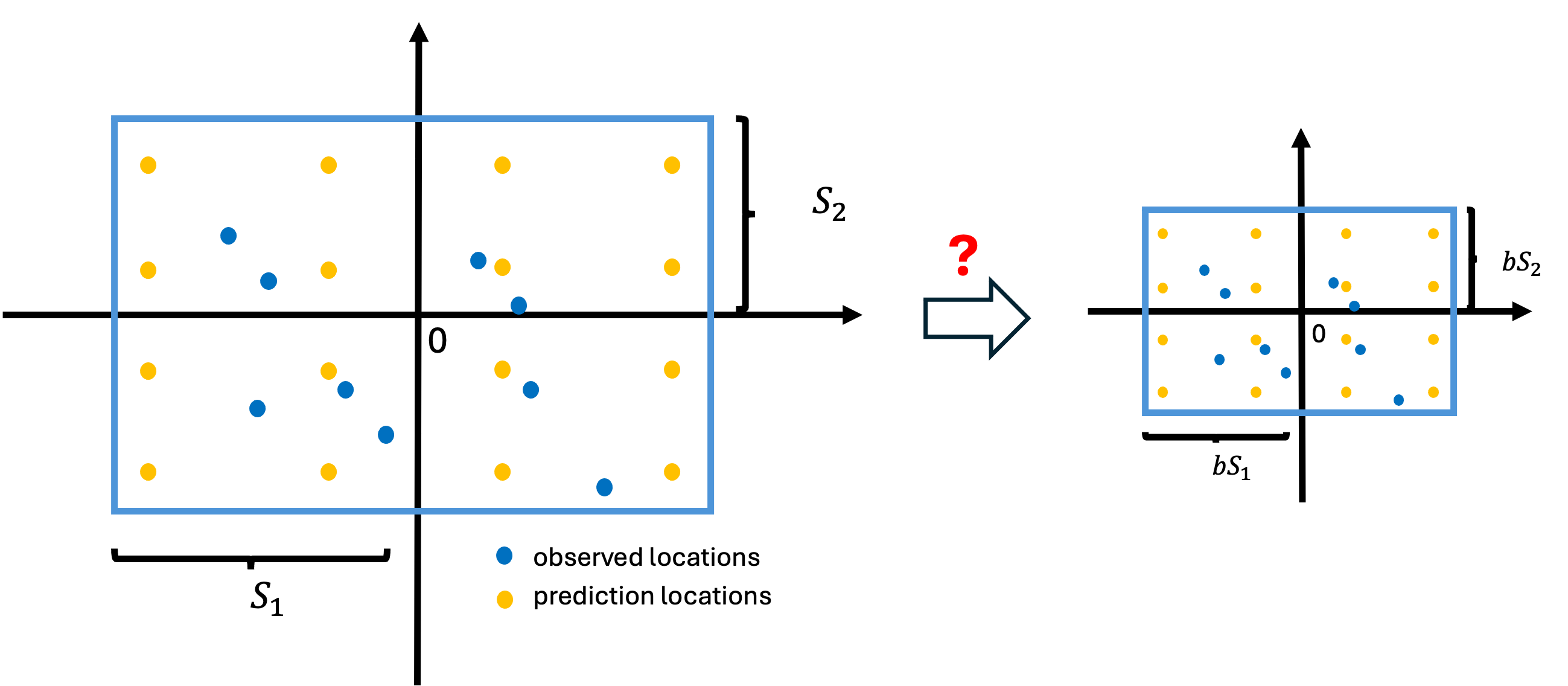
- If we scale the coordinates by a constant \(b\), the length scale \(\rho\) of the underlying GP also needs to be approximately scaled by \(b\) to capture the same level of details in the data.
- We can effectively think of the length scale parameter as \((\rho/\|\mathbf{S}\|)\).
GP vs HSGP spatial intercept posterior mean
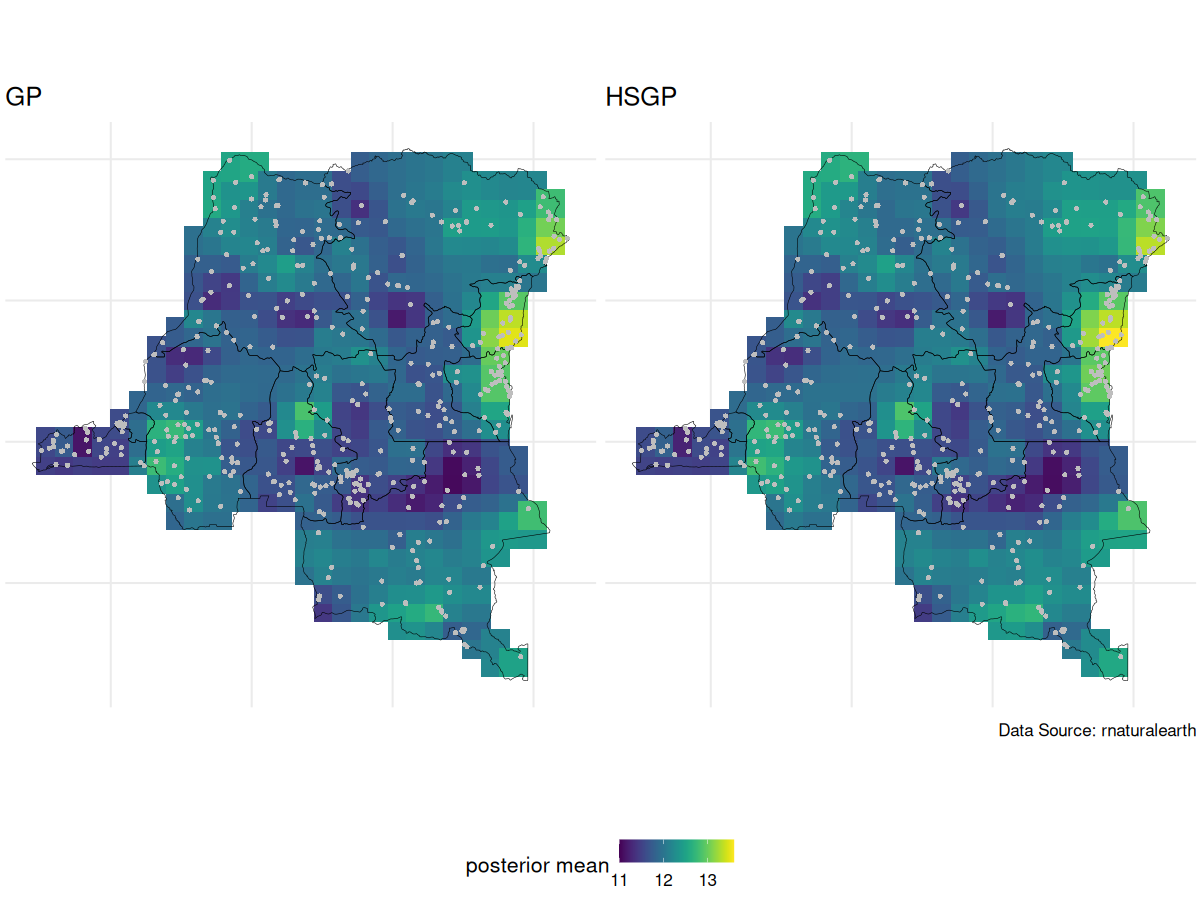
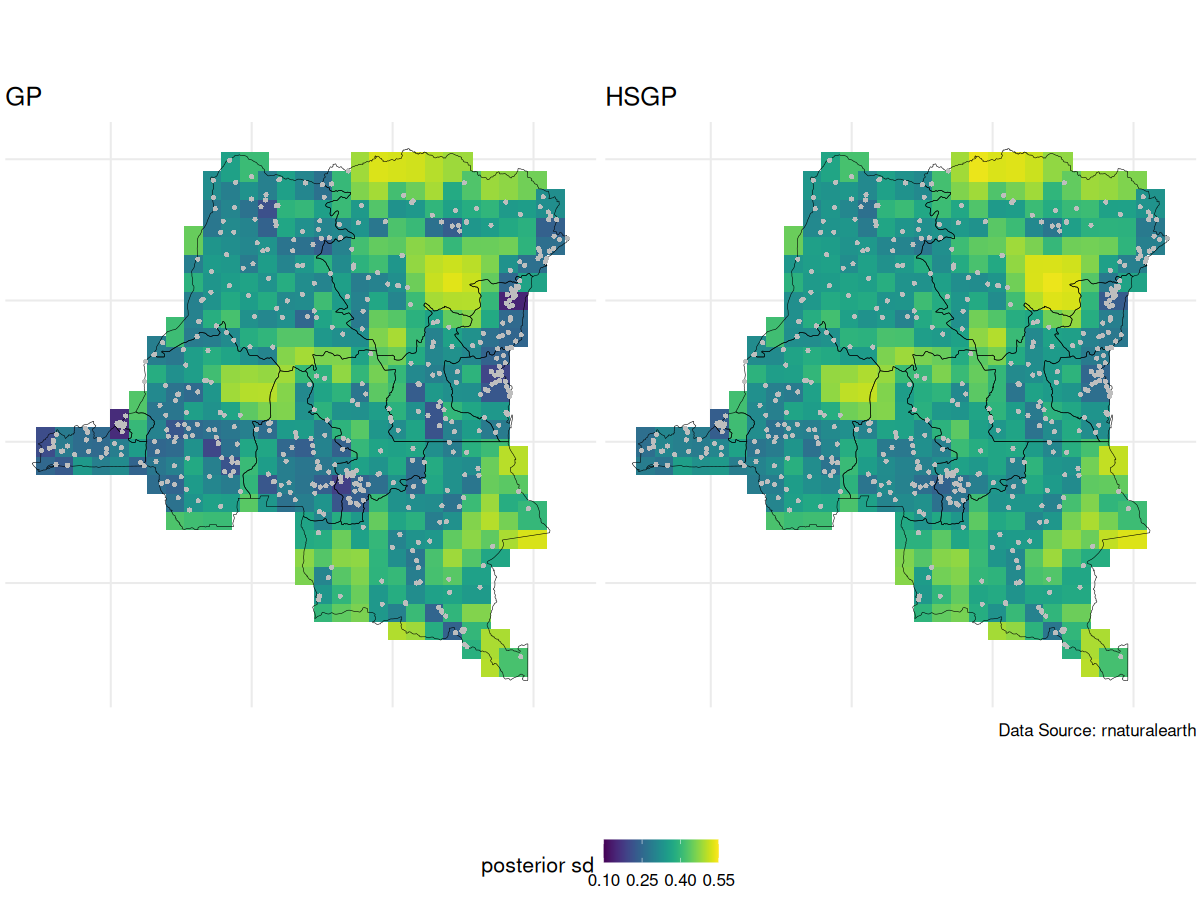
GP vs HSGP spatial intercept posterior SD
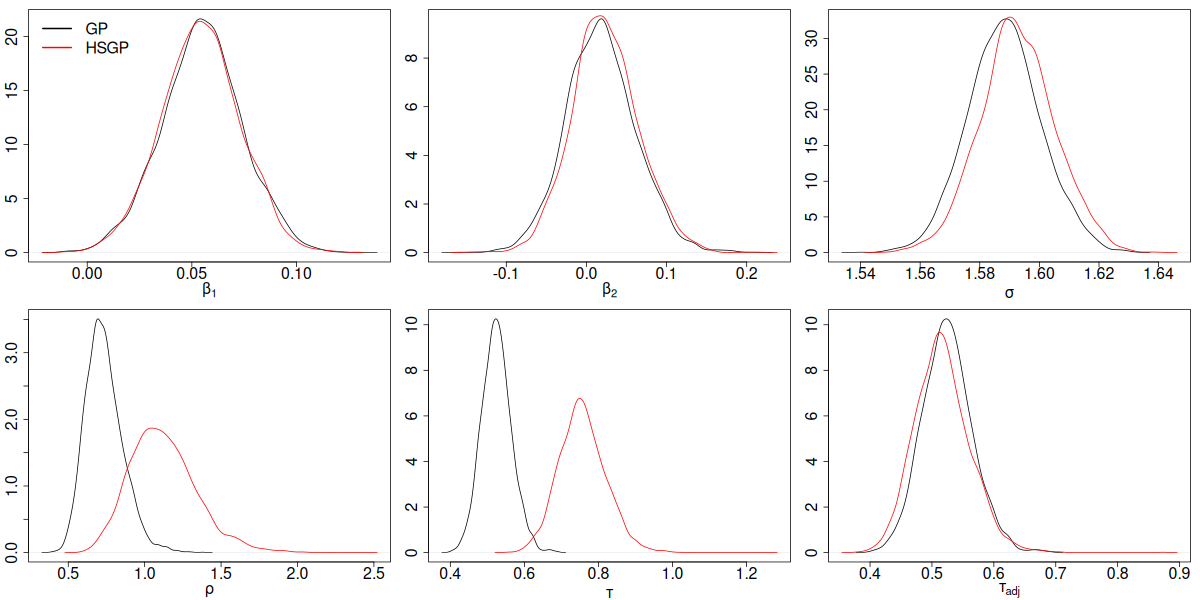
GP vs HSGP parameter posterior density
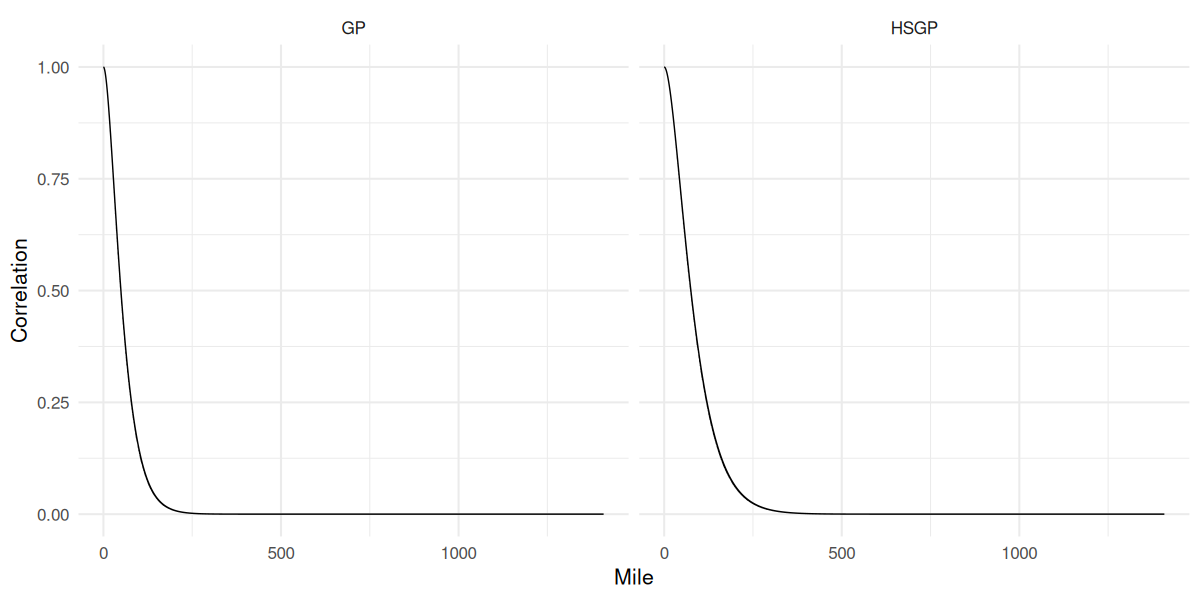
GP vs HSGP correlation function
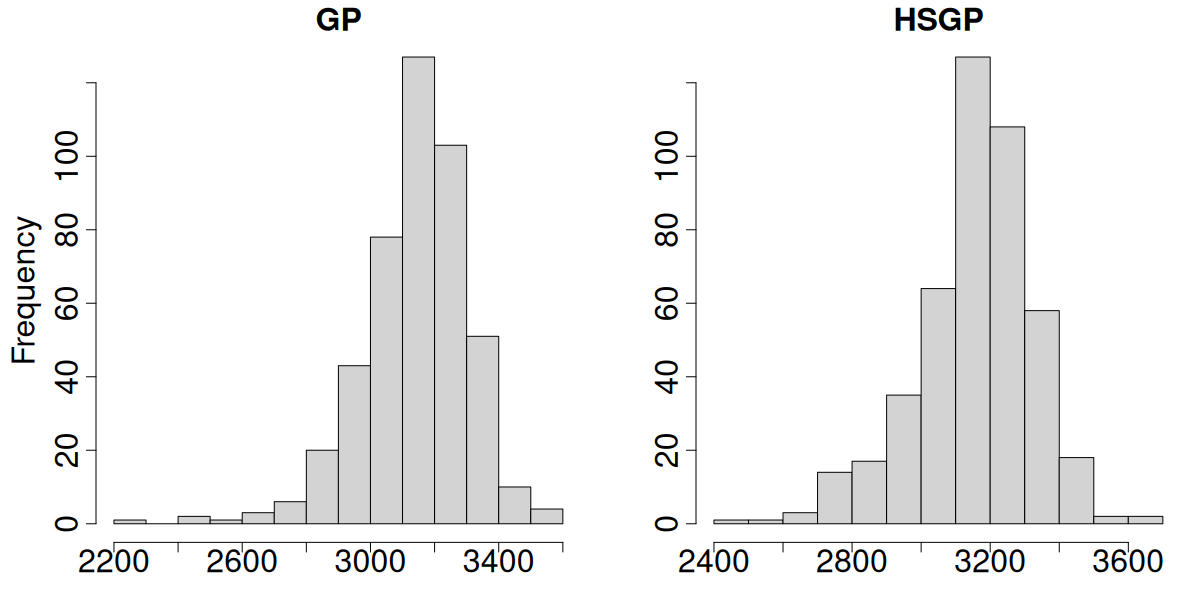
GP vs HSGP effective sample size
References
Riutort-Mayol, Gabriel, Paul-Christian Bürkner, Michael R Andersen, Arno Solin, and Aki Vehtari. 2023. “Practical Hilbert Space Approximate Bayesian Gaussian Processes for Probabilistic Programming.” Statistics and Computing 33 (1): 17.
Solin, Arno, and Simo Särkkä. 2020. “Hilbert Space Methods for Reduced-Rank Gaussian Process Regression.” Statistics and Computing 30 (2): 419–46.
![]()